freq_tidytext_woord <- tidytext_woord %>%
group_by(text) %>%
summarise(aantal = n()) %>%
arrange(desc(aantal)) # sorteren van hoog naar laag19 Analyseren: frequenties en TF-IDF
19.1 Frequenties
De simpelste analyse-methode is het simpelweg tellen hoe vaak een term - vaak een woord of een combinatie van woorden, zoals een N-gram - in een of meerdere documenten voorkomt: de frequentie.
De frequentie kunnen we makkelijk bepalen door met de dplyr::group_by()-functie op de kolom met term te groeperen en vervolgens met de functie n() te bepalen wat de frequentie is.
Hieronder laten we zien hoe je dit voor de data in tidytext_woord en in tidytext_ngram:
19.1.1 Woord
Hieronder zie je de top 10 van meest voorkomende woorden:
# A tibble: 10 × 2
text aantal
<chr> <int>
1 de 12695
2 het 9461
3 van 7606
4 en 4209
5 in 3884
6 college 3801
7 is 3532
8 een 3070
9 voor 2697
10 te 2668Wat direct opvalt is dat er woorden tussen staan die niet nuttig lijken voor een tekstanalyse. Deze woorden worden vaak uit een dataset gefilterd met een zogenoemde lijst stopwoorden.1 Je kunt daarvoor zelf een stopwoordenlijst opstellen, maar voor het gemak gebruiken we een bestaande stopwoordenlijst. Met de anti_join()-functie kun je deze woorden vervolgens uit de lijst filteren. Ook staan er een aantal getallen en losse letters in de dataset. Deze filteren we er óók uit met de str_detect() en nchar()-functies:
stopwoorden <- read_csv("https://raw.githubusercontent.com/stopwords-iso/stopwords-nl/master/stopwords-nl.txt", col_names = F)
freq_tidytext_woord_filter <- freq_tidytext_woord %>%
anti_join(stopwoorden, by = join_by(text == X1)) %>%
filter(!str_detect(text, "[:digit:]|[:punct:]")) %>%
filter(nchar(text) > 1)Na het filteren van de stopwoorden, de getallen en losse letters, zie je hieronder de 10 meest voorkomende woorden:
# A tibble: 10 × 2
text aantal
<chr> <int>
1 college 3801
2 haag 1290
3 den 1278
4 vragen 1075
5 aangeven 750
6 haagse 745
7 gemeente 682
8 gemeenteraad 664
9 pagina 591
10 hart 490Deze gefilterde dataset ziet er al veel bruikbaarder uit, maar het zijn nog steeds veel niet-inhoudelijke woorden waarvan je verwacht dat ze in raadsvragen voorkomen. Gegeven deze context zou je de stopwoordenlijst eventueel aan kunnen vullen met deze veel voorkomende maar niet-inhoudelijke woorden. In het geval van stukken uit de Haagse gemeenteraad zul je er mogelijk de namen van politieke partijen en termen als college, den, haag en gemeenteraad uit willen filteren.
19.1.2 N-gram
Ook voor N-grams geldt dat we deze willen filteren op stopwoorden, getallen en losse letters. Dit willen we echter pas doen nádat de N-grams zijn gegenereerd, omdat je anders N-grams maakt van woorden die niet in die volgorde in de tekst voorkomen.2 Hiervoor doorlopen we de volgende stappen:
- de N-gram opsplitsen in aparte variabelen;
- de afzonderlijke variabelen filteren op de aanwezigheid van stopwoorden;
Daarnaast wordt de dataset ook gefilterd op;
- woorden die getallen of losse leestekens bevatten;
- woorden van 1 karakter (losse letters);
- wanneer de verschillende woorden in de n-gram hetzelfde zijn;
- samenvoegen van de opgesplitste woorden in een 2-gram.
freq_tidytext_ngram <- tidytext_ngrams %>%
separate(text, into = c("woord_1", "woord_2"), sep = " ") %>% # stap 1
anti_join(stopwoorden, by = join_by(woord_1 == X1)) %>% # stap 2
anti_join(stopwoorden, by = join_by(woord_2 == X1)) %>% # stap 2
filter(!if_any(c("woord_1", "woord_2"), # stap 3
~ str_detect(., "[:digit:]|[:punct:]"))) %>%
filter(if_any(c("woord_1", "woord_2"), ~ nchar(.) > 1)) %>% # stap 4
filter(woord_1 != woord_2) %>% # staop 5
unite("text", woord_1, woord_2, sep = " ") %>% # stap 6
group_by(text) %>%
summarise(aantal = n()) %>%
arrange(desc(aantal)) # sorteren van hoog naar laagHieronder zie je de top 10 van meest voorkomende 2-grams of bi-gram:
# A tibble: 10 × 2
text aantal
<chr> <int>
1 den haag 1273
2 college aangeven 694
3 schriftelijke vragen 463
4 volgende vragen 373
5 ris nummer 343
6 college bereid 323
7 overeenkomstig art 271
8 college bekend 260
9 orde stelt 255
10 gemeenteraad ris 211Óók bij deze 2-grams zie je voornamelijk woordcombinaties die waarschijnlijk in veel raadsvragen voorkomen en zou je ook hier de stopwoordenlijst kunnen aanvullen om deze veel voorkomende 2-grams uit de dataset te halen.
19.1.3 Het visualiseren met een tag-cloud
Een veelgebruikte methode om woordfrequenties of n-gram-frequenties te visualiseren is een zogenoemde tag-cloud. Hier zijn verschillende packages voor, maar de twee die het meest gebruikt worden zijn wordcloud en wordcloud2.
Met de package wordcloud maak je een statische tag-cloud en is daarmee geschikt voor statische publicatieformaten, zoals Word-bestanden en PDF. Je maakt een tag-cloud met de volgende code, waarbij we het object freq_tidytext_woord_filter met woordfrequenties gebruiken:
library(wordcloud)
freq_tidytext_woord_filter %>%
with(wordcloud(text, aantal, max.words = 100))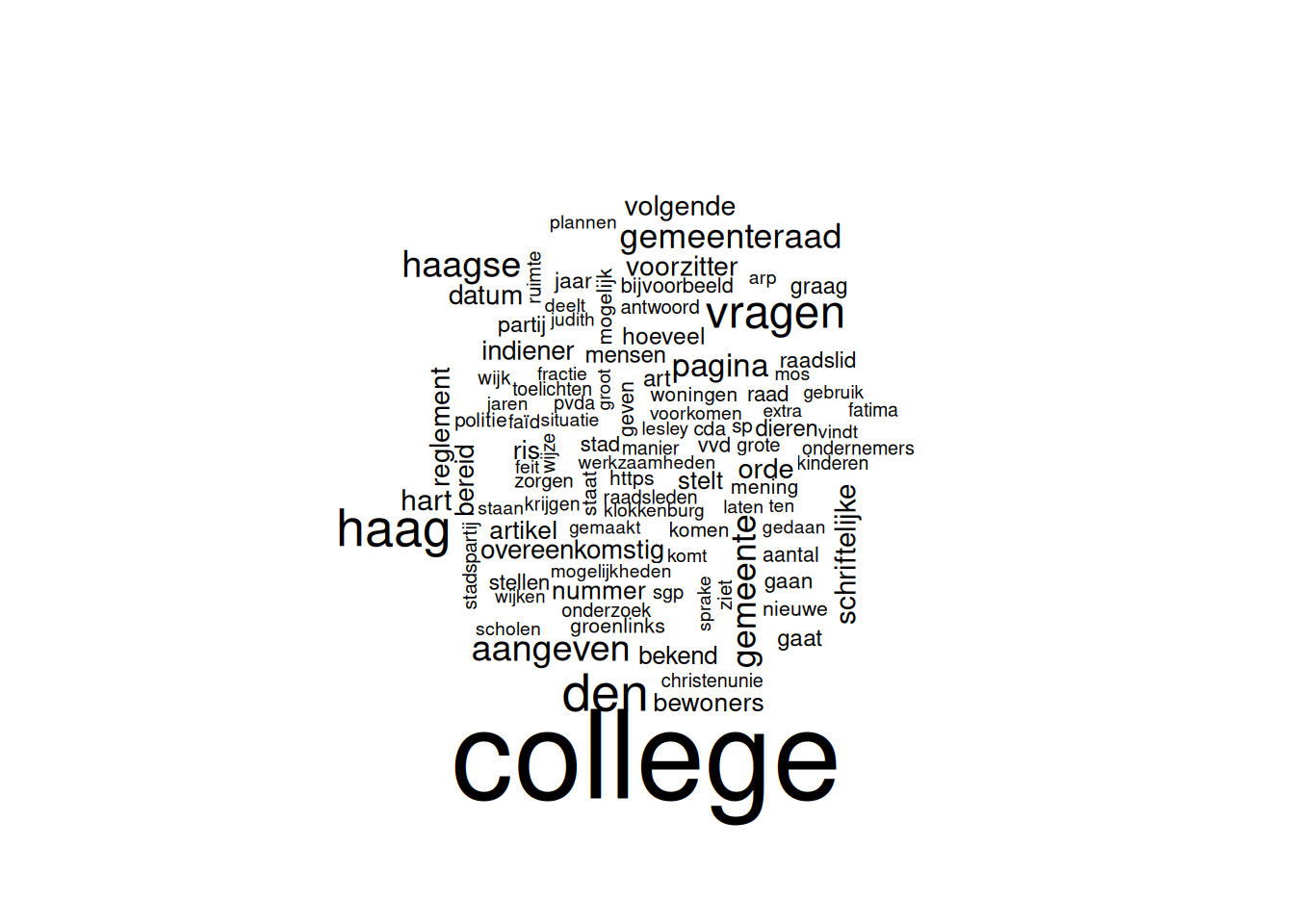
Met wordcloud2 maak je een interactieve tag-cloud. Als je met je muis over een woord of N-gram gaat, komt er bij te staan hoe vaak deze voorkomt en is daarmee geschikt voor interactieve publicaties, zoals een HTML-bestand of een RevealJS-presentatie. Je maakt een tag-cloud dan met de volgende code, waarbij we in dit voorbeeld de 2-gram in het object freq_tidytext_ngram gebruiken:
# Package installeren met install.packages("wordcloud2")
library(wordcloud2)
# freq_tidytext_woord %>%
freq_tidytext_ngram %>%
arrange(desc(aantal)) %>%
head(100) %>%
wordcloud2()19.2 TF-IDF
Frequenties van woorden of n-grams zijn erg interessant om gevoel bij de inhoud van 1 of meerdere teksten te krijgen. Wat zijn thema’s die in het geheel van de teksten veel voorkomen? Maar wat als je wilt weten waarin een specifieke tekst juist verschilt van de rest? Wat zijn de onderwerpen die voor dié specifieke tekst uniek zijn? Dat is waar TF-IDF van pas komt.
TF-IDF staat voor Term Frequency - Inverse Document Frequency en is een maat voor het belang van een term - vaak een woord, maar het kan net zo goed een N-gram zijn - voor een specifieke tekst gegeven het totaal van de teksten.(Tfidf, 2023) Hoe hoger de TF-IDF-score, hoe belangrijker de term.
- Term Frequency (TF)
-
Het aantal keer dat een term in een specifieke tekst voorkomt, gedeeld door het totaal aantal termen in die specifieke tekst.
\[ Term\ Frequency = \frac{Aantal\ keer\ dat\ term\ in\ tekst\ voorkomt}{Totaal\ aantal\ termen\ in\ tekst} \]
- Inverse Document Frequency (IDF)
-
\[ Inverse\ Document\ Frequency\ = \ln\ \left( \frac{Aantal\ documenten}{Aantal\ documenten\ waar\ de\ term\ in\ voorkomt} \right) \]
- Term Frequency - Inverse Document Frequency (TF-IDF)
-
\[ TF-IDF = \frac{Term\ Frequency}{Inverse\ Document\ Frequency} \]
We gaan van elk woord in elke tekst in het object haagse_raadsvragen met de functie bind_tf_idf() de TF-IDF vaststellen. Deze functie vraagt een frequentie van het aantal keer dat een term in een specifiek document voorkomt, dus we groeperen elke tekst op een term en voegen daar een kolom aantal aan toe vóórdat we de functie toepassen:
tf_idf <- haagse_raadsvragen %>%
unnest_tokens(input = text,
output = text,
token = "words") %>%
group_by(bestandsnaam, text) %>%
summarise(aantal = n()) %>%
ungroup() %>%
bind_tf_idf(term = text, document = bestandsnaam, n = aantal)Het resultaat van deze code is een object tf_idf met daarin per term per document de variabelen:
aantal= het aantal keer dat een term in een tekst voorkomttf= de Term Frequencyidf= de Inverse Document Frequencytf_idf= de Term Frequency - Inverse Document Frequency
Met de zojuist berekende tf_idf-score kun je nu per tekst vaststellen wat de meest belangrijke woorden zijn gegeven het totaal van teksten. Voor de raadsvragen in het document 315211_RIS315211 Haags voedselbeleid.pdf zijn in vergelijking met alle andere raadsvragen uit 2023 de 10 belangrijkste woorden bijvoorbeeld:
tf_idf %>%
filter(bestandsnaam == "315211_RIS315211 Haags voedselbeleid.pdf") %>%
select(-bestandsnaam) %>%
arrange(desc(tf_idf)) %>%
head(10)# A tibble: 10 × 5
text aantal tf idf tf_idf
<chr> <int> <dbl> <dbl> <dbl>
1 voedsel 7 0.0143 4.62 0.0663
2 voedselraad 4 0.00820 5.31 0.0436
3 discussiepaper 3 0.00615 6.01 0.0369
4 voedselbeleid 3 0.00615 6.01 0.0369
5 actualisering 2 0.00410 6.01 0.0246
6 programmabrief 2 0.00410 6.01 0.0246
7 tiny 2 0.00410 6.01 0.0246
8 werkagenda’s 2 0.00410 6.01 0.0246
9 duurzaam 3 0.00615 3.70 0.0228
10 aanbod 3 0.00615 3.30 0.0203Het kan natuurlijk óók interessant zijn om een verandering in het gebruik van termen door de tijd heen te meten. Hiervoor kun je bijvoorbeeld de TF-IDF per maand berekenen in plaats van per document. Hiervoor hebben we de maand waarin een vraag is gesteld aan het object haagse_raadsvragen gekoppeld in een nieuw object haagse_raadsvragen_maand.
tf_idf_maand <- haagse_raadsvragen_maand %>%
unnest_tokens(input = text,
output = text,
token = "words") %>%
group_by(maand, text) %>%
summarise(aantal = n()) %>%
ungroup() %>%
bind_tf_idf(term = text, document = maand, n = aantal)Je kunt nu per maand kijken welke termen in díe maand belangrijk waren. Hieronder plotten we van de maanden januari tot men met april de 10 termen met de hoogste TF-IDF-score:3
tf_idf_maand %>%
filter(maand %in% c(1:4)) %>%
group_by(maand) %>%
slice_max(tf_idf, n = 10) %>%
ungroup() %>%
mutate(text = reorder(text, tf_idf)) %>%
ggplot(aes(tf_idf, text, fill = maand)) +
geom_col(show.legend = FALSE) +
labs(x = "tf-idf", y = NULL) +
facet_wrap(~maand, ncol =2, scales = "free")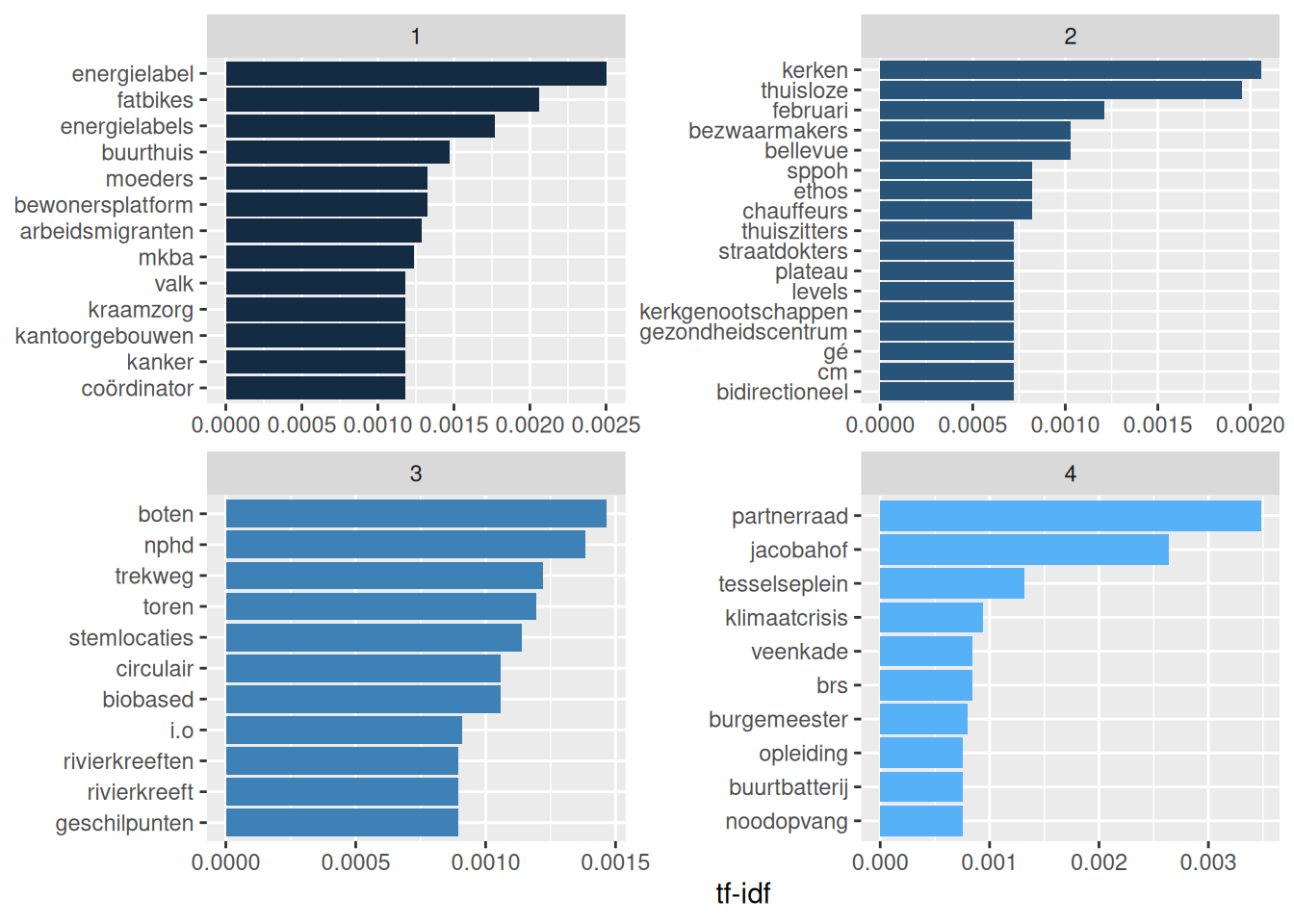
Het karakter van raadsvragen - ze gaan vaak in op de dagelijkse actualiteit - maakt dat een vergelijking over maanden heen misschien niet veel inzichten oplevert. Maar de groepering had ook op het niveau van politieke partijen gemaakt kunnen worden. Of de vraagsteller. Of je zou ook een analyse op andere documenten kunnen doen, bijvoorbeeld op jaarverslagen van scholen. Zie je verschil tussen provincies? Tussen openbaar en bijzonder onderwijs? Tussen basis en voortgezet onderwijs? De mogelijkheden zijn eindeloos!
Lees op Text Mining with R meer over het gebruik van een stopwoordenlijst.↩︎
Lees meer over het filteren van N-grams in het boek Tidy Text Mining with R.↩︎
Je ziet dat sommige maanden méér dan 10 termen met de hoogste TF-IDF-score hebben. Dit komt omdat termen soms dezelfde TF-IDF-score hebben.↩︎